

Dans cet article, je vais vous dire Comment récupérer des données à l’aide de proxys. donc si vous voulez en savoir plus, continuez à lire cet article. Parce que je vais vous donner des informations complètes à ce sujet.
Le grattage de données à l’aide de proxys fait référence à la pratique consistant à utiliser des serveurs proxy pour collecter des données à partir de sites Web ou de sources en ligne tout en préservant l’anonymat et en évitant le blocage IP ou la limitation de débit. Le data scraping, également connu sous le nom de web scraping, consiste à extraire des informations de sites Web, telles que du texte, des images, des prix ou toute autre donnée structurée, à diverses fins telles que la recherche, l’analyse ou la business intelligence.

L’article d’aujourd’hui se concentre sur le même sujet, c’est-à-dire « Comment récupérer des données à l’aide de proxys ». Les articles contiennent chaque élément d’information que vous devez connaître.
Commençons !✨
Comment récupérer des données à l’aide de proxys ?
Vous pouvez évaluer l’importance de la collecte de données pour différentes entreprises dans le monde en prédisant que la création mondiale de données devrait atteindre 180 zettaoctets d’ici 2025 !
Les données sont devenues un atout précieux pour une analyse professionnelle et une meilleure prise de décision.
Il existe une manière traditionnelle de collecter des données, mais c’est une tâche longue et fastidieuse lorsque vous devez parcourir des milliers de sites Web. De nos jours, le web scraping est une alternative efficace à l’extraction de données à partir de sites Web.
Vous pouvez économiser votre temps et vos ressources en utilisant des proxys, des robots et des grattoirs Web pour faire votre travail !
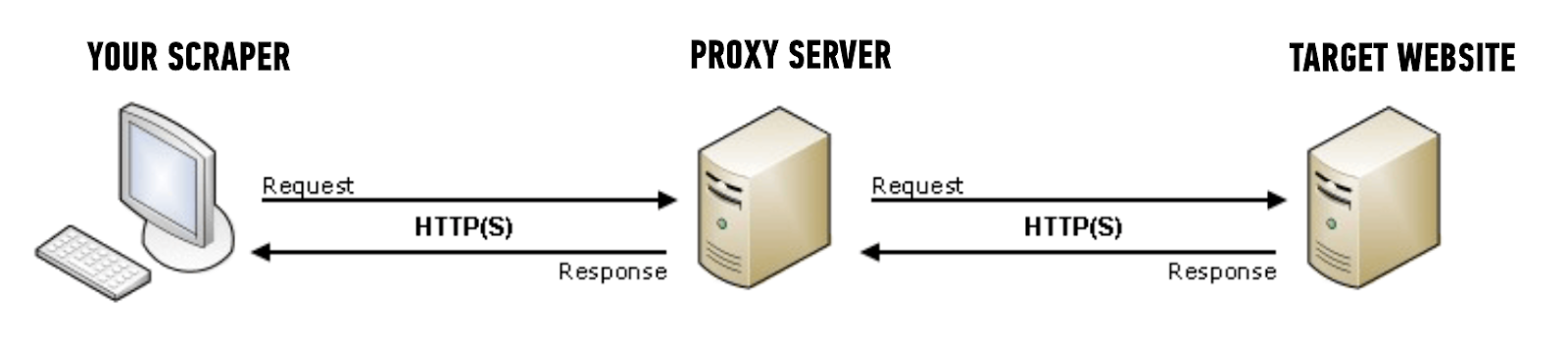
En termes simples, un proxy agit comme un serveur intermédiaire situé entre votre appareil et le site Web cible.
Étant donné que le web scraping nécessite de nombreuses requêtes adressées à un serveur à partir d’une adresse IP, le serveur peut détecter trop de requêtes et bloquer l’adresse IP pour arrêter le scraping ultérieur.
Un proxy peut canaliser vos demandes via une adresse IP différente, masquant ainsi efficacement votre identité et votre emplacement.
Ainsi, le travail ne sera pas entravé et vous pourrez continuer à gratter à mesure que l’adresse IP est modifiée et cela ne posera aucun problème. Cela aide également à masquer l’adresse IP de la machine car cela crée l’anonymat.
Cette possibilité de changer d’adresse IP est à la base d’un grattage de données efficace, vous permettant d’accéder à des sites Web sans révéler votre véritable identité et en évitant les restrictions basées sur l’IP.
Continuez à lire pendant que nous explorons l’art du web scraping à l’aide de proxys, en mettant en évidence les stratégies, les meilleures pratiques et les considérations qui ouvrent la voie à une extraction de données réussie !
Quels sont les types de proxy de Web Scraping ?
Maintenant que vous savez ce qu’est un proxy, passons à certains de ses types largement utilisés. Il existe quatre types principaux de proxy :
1. Proxy du centre de données
Ces proxys proviennent de fournisseurs de services cloud et sont parfois signalés en raison de leur immense utilisation par les utilisateurs. Cependant, comme ils sont moins coûteux, un ensemble de proxys peut être rassemblé pour les activités de web scraping.
2. Proxy IP résidentiel
Étant donné que les proxys résidentiels utilisent les adresses IP des FAI locaux, les sites Web ne peuvent pas dire si le visiteur est un logiciel de grattage ou une véritable personne. Ils sont plus chers que les proxys de centre de données et peuvent donner lieu à des consentements légaux, car le propriétaire ignore que vous utilisez son adresse IP pour des activités de grattage de sites.
3. Proxy IP mobile
Comme leur nom l’indique, les proxys IP mobiles utilisent les adresses IP d’appareils mobiles privés et présentent beaucoup de ressemblances avec les proxys IP résidentiels. Parce que les opérateurs de réseaux mobiles les proposent, ils sont assez chers. Ils peuvent donner lieu à un consentement légal, car le propriétaire de l’appareil ne sait pas si vous utilisez son réseau GSM pour le web scraping.
4. Proxy du FAI
Les proxys résidentiels statiques sont fournis par les serveurs des centres de données et utilisés pour détecter les utilisateurs réels. Les proxys des FAI peuvent être une combinaison de serveurs proxy de centre de données et résidentiels.
Quelles sont les étapes de base pour démarrer le scraping de données à l’aide de proxys ?
Les outils de récupération de données et les proxys ont rendu le processus d’extraction de données relativement plus facile et rapide. Voici quelques étapes de base à suivre pour profiter du data scraping :
1. Choisir le bon type de proxy
La sélection du type de proxy approprié est la première chose à laquelle vous devez penser avant de commencer à récupérer des données.
Il existe deux grandes catégories de proxys : les proxys résidentiels et les proxys de centres de données. Les proxys résidentiels utilisent de véritables adresses IP provenant de fournisseurs de services Internet, offrant un niveau plus élevé d’anonymat et d’authenticité. D’un autre côté, les proxys de centres de données proviennent de centres de données, offrant des vitesses et une évolutivité plus rapides.
Le choix entre les deux dépend de vos besoins spécifiques en matière de scraping, de votre budget et du niveau d’anonymat souhaité.
2. Définir vos objectifs de scraping
La clarté dans vos objectifs de scraping est vitale. Récupérez-vous des données à des fins d’études de marché, d’analyse des concurrents, de surveillance du référencement ou autre ?
La définition de vos objectifs guide votre approche, vous aidant à identifier les sites Web à cibler, les points de données à extraire et l’ampleur de votre opération de scraping.
Prenez le temps de vous poser les questions de base pour vivre une expérience de data scraping fluide !
3. Outils et bibliothèques
L’utilisation des bons outils et bibliothèques peut faciliter efficacement le processus de récupération de données.
Les bibliothèques populaires telles que Beautiful Soup, Scrapy et Selenium offrent des fonctionnalités puissantes pour naviguer dans les structures de sites Web, extraire des données et automatiser les interactions. Ces outils vous permettent d’écrire des scripts qui imitent le comportement de navigation humaine, garantissant ainsi une extraction efficace des données.
Stratégies efficaces pour le grattage de données à l’aide de proxys
Maintenant que vous connaissez les bases et les types, explorons les stratégies qui optimisent vos efforts de récupération de données à l’aide de proxys :
1. Rotation IP pour l’anonymat
L’un des principaux avantages des proxys est leur capacité à alterner les adresses IP. La rotation IP implique de modifier périodiquement l’adresse IP que vous utilisez pour le scraping. Cette approche dynamique imite le comportement de navigation naturel et empêche les sites Web de détecter et de bloquer vos activités de scraping sur la base d’une seule adresse IP.
2. Implémentation de limites de débit
Le scraping responsable implique de respecter les conditions d’utilisation et les limites de tarifs des sites Web. En contrôlant la fréquence et le volume de vos requêtes, vous évitez de surcharger les serveurs et maintenez une interaction fluide avec le site internet. Les proxys facilitent les limites de débit en vous permettant de distribuer les requêtes sur plusieurs adresses IP.
3. Gestion des Captchas et des Cookies
Les sites Web déploient souvent des captchas et des cookies pour faire la distinction entre les utilisateurs humains et les robots. Les proxys peuvent vous aider à relever ce défi en vous permettant de contourner les captchas et les cookies ou en alternant les adresses IP pour éviter de déclencher ces mécanismes de sécurité.
4. Contourner les restrictions de géolocalisation
Certains sites Web restreignent l’accès à des régions spécifiques. Les proxys vous permettent de choisir une adresse IP à partir d’un emplacement souhaité, contournant efficacement les restrictions de géolocalisation et vous permettant de récupérer des données spécifiques à une région.
De plus, le scraping de contenu géociblé est en augmentation : plus de la moitié des spécialistes du marketing utilisent des proxys pour collecter des données spécifiques à une région pour des campagnes marketing localisées et le ciblage d’audience.
5. Surveillance de l’état du proxy
L’efficacité de votre opération de scraping dépend de la santé de vos proxys. Surveillez régulièrement les performances, la vitesse et la fiabilité de vos proxys pour garantir une extraction de données sans faille. Les outils de gestion des proxys peuvent vous aider dans ce processus en vous fournissant des informations sur l’état des proxys.
Meilleures pratiques pour le grattage éthique des données
Les considérations éthiques sont primordiales dans le processus de grattage de données. Vous pouvez suivre ces bonnes pratiques non seulement pour maintenir votre réputation, mais également pour garantir que vos activités de scraping sont conformes aux normes juridiques et éthiques :
1. Respectez le fichier Robots.txt
De nombreux sites Web disposent d’un fichier robots.txt qui indique quelles parties du site Web peuvent ou ne peuvent pas être récupérées. Le respect des directives du fichier robots.txt présente des pratiques de scraping éthiques et évite les conflits inutiles.
2. Évitez de surcharger les serveurs
Pratiquer un scraping responsable implique d’éviter les requêtes agressives et excessives qui pourraient surcharger les serveurs. Mettez en œuvre des limites de débit, des retards et une rotation des adresses IP pour garantir que vos activités de scraping ne perturbent pas les opérations du site Web.
3. Adhérer aux conditions d’utilisation
Lisez et respectez les conditions d’utilisation des sites Web que vous avez l’intention de gratter. Certains sites Web interdisent explicitement les activités de scraping. Le respect de leurs conditions non seulement maintient les normes éthiques, mais évite également les conséquences juridiques potentielles.
4. Choisissez des fournisseurs de proxy réputés
Sélectionnez des proxys auprès de fournisseurs réputés, comme Proxy intelligent par Crawlbase, qui offrent des services fiables et de haute qualité. Ces fournisseurs de proxy fiables garantissent que les adresses IP que vous utilisez sont légitimes, réduisant ainsi le risque d’interdiction et améliorant le taux de réussite de vos tâches de scraping.
Conclusion:)
Le scraping de données avec des proxys est un outil puissant fournissant de nombreuses informations et informations. Selon une étude, environ 26 % des internautes utilisent des serveurs proxy pour surfer sur le Web.
En sélectionnant le bon type de proxy, en définissant vos objectifs de scraping, en utilisant des outils appropriés et en suivant les directives éthiques, vous pouvez naviguer dans les complexités du Web et extraire des données précieuses tout en respectant les limites fixées par les sites Web.
La technique de récupération de données utilisant des proxys vous permet, à vous et à votre entreprise, de profiter de la puissance de l’information pour prendre des décisions basées sur les données.
A lire aussi 🙂
J’espère donc que vous avez aimé cet article sur Comment récupérer des données à l’aide de proxys. Et si vous avez encore des questions ou des suggestions à ce sujet, vous pouvez nous le faire savoir dans la zone de commentaires ci-dessous. Merci beaucoup d’avoir lu cet article.