


Lorsque Google a décidé de mettre à jour ses documents officiels en juin 2022, les praticiens et les spécialistes du référencement ont commencé à s’inquiéter d’un élément de contenu particulier qui a été ajouté à la limite d’exploration de Googlebot. La documentation officielle de Googlebot contient la déclaration suivante :
“Googlebot peut explorer les 15 premiers Mo d’un fichier HTML ou prendre en charge un fichier texte. Toutes les ressources référencées dans le HTML telles que les images, les vidéos, le CSS et le JavaScript sont récupérées séparément. Après les 15 premiers Mo du fichier, Googlebot arrête l’exploration et ne considère que les 15 premiers Mo du fichier pour l’indexation. La limite de taille de fichier est appliquée aux données non compressées…”
Source : Googlebot
Qu’est-ce que Googlebot ?
Googlebot est le nom générique officiel du robot d’exploration de sites Web de Google. Il est actuellement responsable de la collecte d’informations sur votre site Web pour l’évaluation du référencement. Il fournit des informations essentielles à Google sur l’opportunité d’indexer ou non une page Web.
Googlebot est séparé en deux types : Googlebot Desktop et Googlebot Smartphone. Comme son nom l’indique, ces deux éléments travaillent main dans la main pour déterminer si Google doit indexer un site Web sous les plates-formes Desktop et Mobile.
Alors, comment la limite d’exploration Googlebot de 15 Mo tient-elle compte de tout cela ?
Limites de la limite d’exploration de 15 Mo
La limite d’exploration de 15 Mo est la limite standard définie pour Googlebot Desktop et Smartphone. S’applique uniquement au texte encodé dans le fichier HTML ou le fichier texte pris en charge de la page Web.
Cela se traduit par la limite d’exploration de Googlebot définissant ses limites dans le texte de votre fichier HTML. Les mêmes textes peuvent être trouvés chaque fois que l’on inspecte la source de la page d’une page Web.

Mais qu’est-ce que cela signifie pour les images, les vidéos, les ressources CSS et JavaScript utilisées dans le fichier HTML ? Considérez le texte cité ci-dessous,
“…les ressources référencées en HTML telles que les images, les vidéos, le CSS et le JavaScript sont récupérées séparément…”
Cette déclaration signifie simplement que la limite d’exploration de 15 Mo pour Googlebot ne tient pas compte de la taille des fichiers des ressources référencées dans un fichier HTML. Par exemple, lorsqu’une image apparaît sur une page Web, elle est généralement définie par une ligne de code.

Chaque fois qu’une image est définie via une URL, cela NE tient PAS compte de la limite d’exploration de 15 Mo. En effet, l’image est “référencée” à partir d’une URL différente plutôt que d’être “encodée” dans le fichier HTML lui-même.
La différence entre le référencement et l’encodage
Le référencement d’un média ou d’une ressource dans un fichier HTML signifie qu’il n’est appelé ou accessible qu’à partir d’une URL différente en dehors de votre page Web. Comme une personne plaçant un objet dans son sac au lieu de le porter. De cette façon, il est plus facile de stocker et d’accéder à l’objet tout en conservant une liberté de mouvement. Quand quelque chose est “encodé”, cela se traduit par placer un fichier purement sur un autre. Une personne qui préfère transporter un objet qui limite son mouvement dans le processus.
Il n’existe actuellement aucun moyen d’encoder un fichier multimédia comme une image ou une vidéo dans votre fichier HTML. Mais d’un autre côté, il est possible d’encoder des codes CSS et JavaScript dans un fichier HTML.
Qu’est-ce que cela implique ?
L’inclusion de ces codes dans votre fichier HTML contribue à des lignes de code supplémentaires. Et des lignes de code supplémentaires permettent à votre fichier HTML d’atteindre la limite d’exploration Googlebot de 15 Mo.
La vérité sur la limite d’exploration Googlebot de 15 Mo
C’est un fait qu’un constructeur de pages Web n’atteindra presque jamais la limite d’exploration Googlebot de 15 Mo définie pour l’indexation d’un fichier HTML. Dans un tweet de John Mueller, un défenseur de la recherche chez Google ; Atteindre les 15 Mo dans votre fichier HTML équivaut à environ 16 romans dont le manuscrit est transféré dans un fichier HTML.
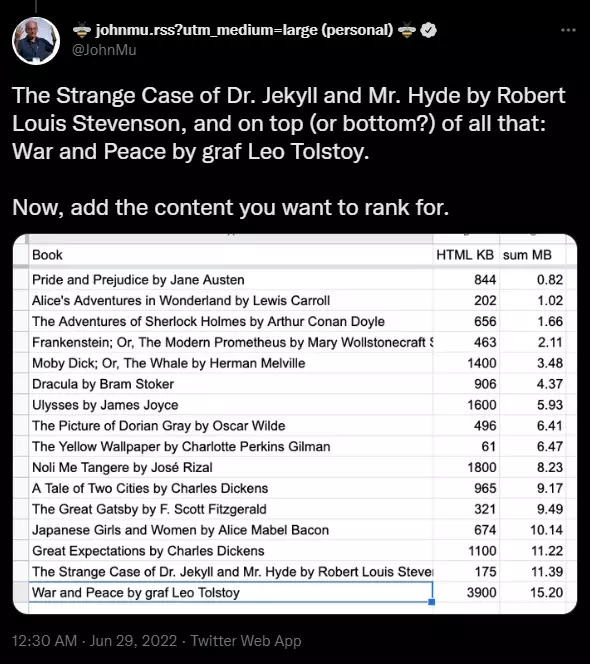
La source: Twitter
Du point de vue d’un développeur, c’est considéré comme une quantité absurde de lignes de code à placer dans votre code HTML. Il y aura toujours des moyens efficaces de créer une page Web, en particulier la vitesse du site étant considérée comme un facteur important dans le classement des sites Web. Si vous souhaitez tester la taille d’un fichier HTML pour une page Web, envisagez d’utiliser l’outil HTML Size Analyzer de DebugBear.
Limite d’exploration de 15 Mo de Googlebot et vitesse du site
Ne pas pouvoir atteindre la limite d’exploration Googlebot de 15 Mo ne devrait pas être une excuse pour ignorer les optimisations de la vitesse d’un site Web. Google considère l’expérience utilisateur comme l’un des principaux facteurs affectant le classement des sites Web. Cela implique la vitesse à laquelle un navigateur Web peut charger les ressources et les éléments d’une page Web.
La limite d’exploration est destinée à servir de guide pour l’indexation et ne garantit pas le classement. Le fait que le fichier multimédia et les ressources ne soient pas pris en compte dans la limite d’exploration n’est pas une excuse pour ignorer les ressources chargées par un navigateur Web.
La vitesse du site doit toujours être prise en compte lors du référencement de médias ou de ressources sur votre site Web.
En savoir plus sur l’optimisation de la vitesse du site ici.
Clé à emporter
La nouvelle déclaration incluse dans la documentation officielle de Googlebot concernant la limite d’exploration de Googlebot à 15 Mo ne devrait pas intimider les praticiens et les spécialistes du référencement. Il devrait plutôt servir de rappel pour garder à l’esprit comment une page Web conviviale pour le référencement doit être construite.
Même avec les récents algorithmes de Google récompensant une stratégie de référencement basée sur le contenu, il est presque impossible d’atteindre la limite de crawl de 15 Mo pour une seule page Web. L’expérience utilisateur, la vitesse du site et la publication continue de contenu unique sont toujours la priorité dans la création d’un site Web bien optimisé.
Si vous souhaitez en savoir plus sur la création d’un site Web bien optimisé et optimisé pour le référencement, consultez Learn SEO: The Complete Guide for Beginners!